반응형
GraphQL 이란
META에서 개발한 Query Language over HTTP.
SQL이 Application → DB로 데이터를 쿼리하는 언어라면, GraphQL은 Application → Server로 데이터를 쿼리하는 언어
GraphQL is for…

Client ↔︎ Server 간의 Data Provide Mismatch를 해결하기 위해 개발된 언어
No more Overfetching, Underfetching
데이터의 제공 주체는 서버이며, 서버는 다수의 client를 위한 서비스를 제공하기 때문에, 데이터에 기반하여, API를 제공한다.
이에 client는 필요한 Data 이외의 데이터를 함께 제공받거나(overfetching), 필요한 데이터를 모으기 위해 여러번 호출 (underfetching, n+1) 해야 하는 상황이 발생할 수 있다.
Client n+1?
client가 특정 게시자의 게시글 내용 전체를 쿼리하고 싶다면
일반적으로 다음의 과정을 따른다
1. GET /xx/list API를 통해 xx의 특정 게시자 게시글 list를 받는다
2. GET /xx/{id} API를 통해 1번 쿼리된 게시글 수 만큼 요청한다.
이에 list요청 1번, 세부 게시글 n번의 요청이 필요하다.
서버에서 전용 API를 만들어 줄 수 있지만, 이는 장기적으로 부적절하다.
GraphQL 장단점
장점
1. Overfetching, Underfetching을 해결할 수 있다.
+응답 Size를 줄일 수 있다.
2. Endpoint 및 request parameter, response Object 등 정의를 줄인다.
3. 데이터 제공 로직이 간소화된다.
- Data의 Depth와 상관없이 한번에 쿼리가 가능하다.
- 표준화된 요청 로직 작성 가능
- 한번에 여러 Type의 Data를 쿼리 할 수 있다.
4. 서버 ↔︎ 클라이언트의 커플링 일부 감소 효과… (ex: data type 변경 시 api 사용자가 아닌, 해당 데이터를 사용하는 client에게만 영향)
단점
1. 서버 ↔︎ 클라이언트 간의 소통방식의 변화: client는 Data 구조에 대한 이해가 필요하고, server는 client에게 데이터 변화를 고지해야 함
2. Data 설계의 복잡성 증가: client가 쿼리를 작성하기 때문에, Data 설계 시 많은 경우의 수를 고려해야 함
3. HTTP 캐싱 이점을 활용하기 힘들다: Endpoint가 하나 이기 때문
4. 에러 핸들링 난이도가 상승: 하나에 요청에 n개의 에러가 발생할 수 있기 때문
5. 요청 및 응답이 무거워질 수 있다: 뎁스가 높아지거나, 데이터 자체가 큰 경우에 대해 서버에서 핸들링 하기가 힘들다
6. MSA 구조에 대응하기 위해 다른 솔루션이 필요: MSA 구조에서 client가 각 서버로 graphQL 쿼리를 하면, 기존 목적에 위배되는 상황 발생 (후술)
7. 파일업로드는 통합 불가
Concepts
Document
query {
author(limit: 5) {
id
name
articles {
id
title
content
}
}
}GraphQL의 Request String(Body)를 documnet라고 한다.
Fields
author, id, name, article, id, title, content가 field이다.
Arguments
author(limit: 5)의 limit 부분이 Arguments이다.
Variables
{
limit: 5
}
query($limit: Int) {
author(limit: $limit) {
id
name
articles {
id
title
content
}
}
}위 쿼리의 Argument를 Variables로 바꿔서 쓰는 방법
limit: 5로 variable을 선언하고, 쿼리에서 해당 variable을 사용한다.
Aliases / Fragments
// Alias
query fetchAuthor {
author(id: 1) {
name
profile_pic_large: profile_pic(size: "large")
profile_pic_small: profile_pic(size: "small")
}
}
// Fragments
fragment authorFields on author {
id
name
profile_pic
created_at
}
query fetchAuthor {
author(id: 1) {
...authorFields
}
}
query fetchAuthors {
author(limit: 5) {
...authorFields
}
}Alias는 response 받을 값을 다르게 지정하여 return 받기 위한 방법
Fragments는 query template를 만들어서 재사용하기 위한 방법
Operation
GraphQL는 크게 3가지 동작을 가진다.
1. Fetching: Read dataMutation:
2. CUD data
3. Subscription: Realtime update (over websocket)
Fetching
{
author {
id
name
}
}author의 id와 name을 쿼리하는 예시
Mutation
mutation {
insert_todos(objects: [{ title: "New Todo" }]) {
returning {
id
title
is_completed
is_public
created_at
}
}
}“new todo”라는 object를 insert하고, response로 id 등 서버 생성 값을 받는 예시
Subscription
subscription {
todos {
id
created_at
is_completed
is_public
title
}
}todos에 대한 신규 데이터를 실시간으로 제공 받는 operation 예시
Apollo Federation
MSA 구조에서 GraphQL을 적용하게 되면, 수 많은 서버로 각각 GraphQL요청을 보내야 한다.
이는 over/underfetching을 방지하기 위한 GraphQL의 근본 사상을 위협하게 된다.
Apollo팀에서는 이를 해결하기 위해 router를 통한 graph 연동으로 솔루션을 제공한다.
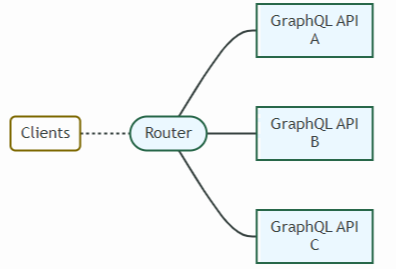
Router는 Root로 할당되며, 각 GraphQL API 서버들을 하위 뎁스로 갖는다.
client는 router를 통해 GraphQL 통신을 하며, Router가 각 API 서버로 Data를 Fetching해주는 역할을 한다.
사례 & 인사이트 (중복 내용 제거)
Naver (2020)
강점:
- 강력한 개발자 경험 제공: Client가 Data Schema를 이해하고 쿼리를 작성할 수 있음, 이는 투명한 정보를 통해 client의 책임 있는 API 호출을 유도함
- 성능 이점: 모바일 디바이스처럼 한정된 네트워크 대역폭 또는 한정된 리소스인 경우, 원 쿼리를 통한 데이터 access는 큰 이점을 가짐
- 안정적인 subscription: 원하는 data만 구독하여 실시간 데이터 처리를 효율적으로 할 수 있음

- Schema 관리를 위한 모니터링 툴이 필수
- schema 버전 관리가 필수
- Data Schema 설계를 GraphQL의 관계 중심으로 설계해야 함
- Data Graph를 관리하기 위한 비용이 적지 않음
Kakao
gql은 퍼포먼스적인 장점이 분명 존재합니다. 하지만 개인적으로 더 관심이 가는 장점은 바로 생산성 향상입니다. gql은 기존 백앤드-프론트앤드 협업 문화를 많이 바꿀것으로 예상합니다. gql의 협업 구조상 프론트앤드쪽에 조금 더 할일이 많아지고 힘이 실리는 느낌입니다. 에자일하게 웹사이트 프로젝트를 진행하는데 gql이 많은 도움이 될 것이라고 생각합니다.
개발자 여러분에게 안타까운 소식을 전하자면, 이 글을 읽었다고 해서 gql을 바로 실전에서 사용하기는 쉽지 않을 것입니다. 이 글에서는 gql의 클라이언트 모듈에 대해서는 구체적으로 언급하지도 않았습니다. 특히 react를 혼합해서 사용하려면, 또 다시 가파른 고개를 넘어서야 제대로 사용 할 수 있을 것입니다.
…
Google Cloud
그래프를 데이터 중심 계층 구조로 취급
- GraphQL은 Data에 Access 할 수 있는 하나의 계층으로 취급해야 합니다.
- REST의 /a의 GET, POST는 a 객체를 조회/추가 한다고 하듯이, GraphQL의 Query 및 operation도 그러해야 합니다.
- GraphQL을 활용할 때 빠지기 쉬운 함정은 operation 시 이를 함수처럼 사용하는 경우 입니다.
- 함수로 취급하여 operation하면, 점점 데이터 스키마와 멀어지게 되며, 이는 schema를 더 이상 관리할 수 없는 상황이 발생 함
GraphQL을 고집하지 않기
- GraphQL은 항상 최선의 선택이 아니라는 것을 염두 해야 한다.
- GraphQL은 REST의 대체제가 아닌, 선택사항이며, 데이터 구조 상 REST가 더 적합한 경우도 많다.
- 가령 4번째 depth안의 모든 name에 대한 조회를 한다면, graphQL은 쿼리의 비대함 뿐 아니라, 서버의 부답을 작용할 것
AWS
GraphQL이 유리한 경우
- 대역폭이 제한되어 있으며 요청 및 응답 수를 최소화하려는 경우
- 여러 데이터 소스가 있고 이를 하나의 엔드포인트에서 결합하려는 경우
- 고객의 요청이 매우 다양하고 기대하는 응답도 크게 다른 경우
REST가 유리한 경우
- 애플리케이션 규모가 작고 데이터가 덜 복잡한 경우
- 모든 클라이언트에서 유사하게 사용되는 데이터와 작업이 있는 경우
- 복잡한 데이터 쿼리가 필요 없는 경우
Conclusion
GraphQL 도입 시의 이점 대비 리스크 및 단점이 너무 크게 다가온다.
장단점을 미루어 보았을 때, 비즈니스 Data 구조가 depth가 적고 wide하게 확장되는 상황에서 매우 유용할 것으로 생각된다.
- depth가 늘어날 수록 서버의 성능 부담이 크게 증가한다. 하지만, 클라이언트가 서버의 부담을 고려하여 쿼리를 하는 것은 말이 안된다. 반면 wide한 data가 많아질 수록 클라이언트의 호출 수가 증가하게 된다.
여러 사례를 보았을 때, 비즈니스 또는 데이터 구조에 따라서 GraphQL 도입 여부를 결정하는 것이 바람직 하다.
REFERENCE
https://hasura.io/learn/graphql/intro-graphql/core-concepts/
https://www.howtographql.com/basics/1-graphql-is-the-better-rest/
https://www.apollographql.com/docs/federation/
https://deview.kr/data/deview/session/attach/1100_T1_박성현_GraphQL API 까짓거 운영해보지 뭐.pdf
반응형
'개발 일지' 카테고리의 다른 글
| Hot vs Cold Publisher (Projectreactor Advanced Features) (0) | 2024.02.19 |
|---|---|
| Clean Code in Reactive (1) | 2024.01.25 |
| Netflix OSS란 (feat. Service Mesh) (0) | 2024.01.05 |
| Jenkins Docker Builder 연동 이슈 (connection refused) (1) | 2023.12.20 |
| Micrometer Log Tracing (feat. Spring Boot 3) (0) | 2023.12.14 |