반응형

Parallel Consumer란?
Confulent.inc에서 개발한 Open Source로 consumer의 consume이 parallel 하게 동작하도록 구현했다.
주요 목적은 분산 Consume을 위해 partition이 과도하게 늘아나는 비합리성을 해결하기 위함이다.
Before
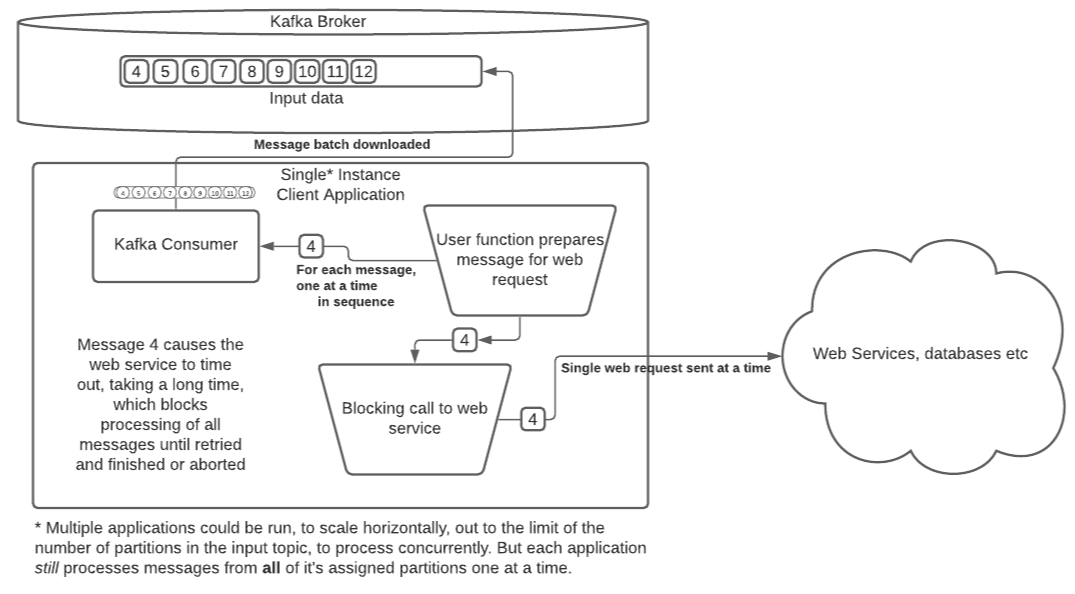
기존 Consumer의 구조는 Consume의 주체는 Single Thread로 동작한다.
1. Consumer는 설정된 size 만큼 message를 읽는다(consume).
2. 설정된 offset 전략에 따라서 모든 message 처리가 완료될 때 까지 blocking 한다.
위 그림은 consume 프로세스 중 delay 될 수 있는 상황을 도식화했다.
4번 message가 web request 이슈로 delay 되면 전체 consume 퍼포먼스가 낮아진다.
After
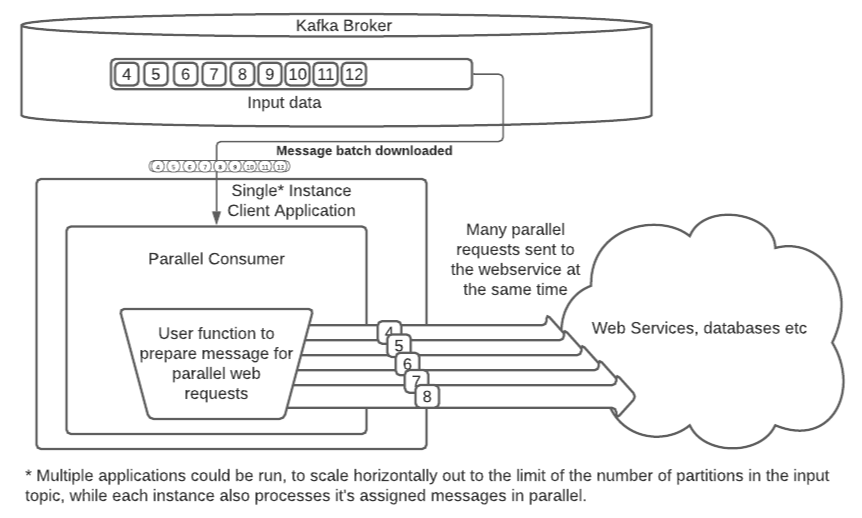
Parallel Consumer는 위 상황을 해소하기 위해 개발되었다.
목표는 consume을 parallel 하게 동작하여 하나의 파티션에 여러 consumer가 동작하는 효과를 보는 것이다.
Overview
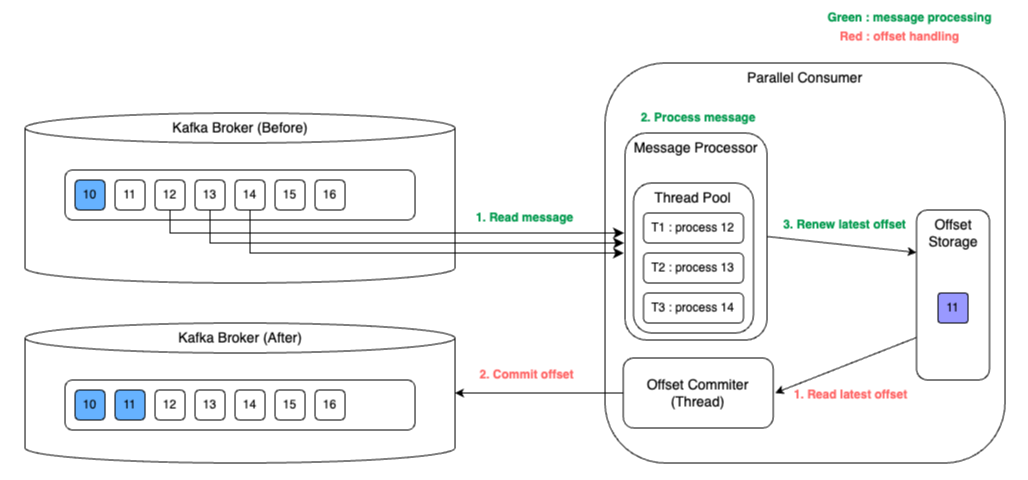
- consumer가 consume을 병렬로 처리할 수 있도록 Thread Pool을 관리한다.
- offset 관리를 위해 Offset Storage에 완료된 offset이 update 된다.
- Offset Commiter가 비동기로 완료된 offset을 선정하여 commit 한다.
ParallelConsumerOptions
Order
public enum ProcessingOrder {
UNORDERED,
PARTITION,
KEY
}ParallelConsumer는 순서보장 관련하여 3가지 옵션을 지원한다.
- UNORDERED: 순서보장 없이 모든 Key에 대해서 shard를 생성
- PARTITION: 파티션 단위로 shard를 생성, 파티션단위로 순서보장
- KEY: KEY 단위로 shard를 생성하여 key별 순서를 보장
// default order: KEY
Shard란?
Local에서 생성되는 Queue로 worker에게 할당할 work를 큐잉 한다.
자세한 사항은 후술
CommitMode
public enum CommitMode {
PERIODIC_TRANSACTIONAL_PRODUCER,
PERIODIC_CONSUMER_SYNC,
PERIODIC_CONSUMER_ASYNCHRONOUS
}CommitManager가 수행할 commit 전략에 대한 설정
- PERIODIC_TRANSACTIONAL_PRODUCER: Streams 등 consume->produce에 transaction을 지원하는 commit 전략
- PERIODIC_CONSUMER_SYNC: 주기적으로 sync 하게 commit을 수행
- PERIODIC_CONSUMER_ASYNCHRONOUS: async 하게 commit 요청을 보냄, 속도가 제일 빠름
// default commitMode: PERIODIC_CONSUMER_ASYNCHRONOUS
// default auto commit interval ms: 5000ms
InvalidOffsetMetadataHandlingPolicy
public enum InvalidOffsetMetadataHandlingPolicy {
FAIL,
IGNORE
}offset handling 도중 에러가 발생한 상황의 정책 설정
- FAIL: 발생 시 shutdown
- IGNORE: 발생 시 무시
// default: FAIL
기타
private final Duration sendTimeout = Duration.ofSeconds(10);
private final Duration offsetCommitTimeout = Duration.ofSeconds(10);
private final Integer batchSize = 1;
private final Duration thresholdForTimeSpendInQueueWarning = Duration.ofSeconds(10);
private final int maxFailureHistory = 10;
public final Duration shutdownTimeout = Duration.ofSeconds(10);
public final Duration drainTimeout = Duration.ofSeconds(30);
public final int messageBufferSize;기타 적용 가능한 설정들
동작원리
전체적인 동작과정은
1. Poll Task가 executor로 pooling 되어 broker로부터 record를 poll 함
2. poll 된 record를 mailbox(BlockingQueue)로 add
3. control Task가 executor로 pooling 되어 commit 트리거 및 userFunction submit을 담당
4. OffsetCommitter가 offset처리를 담당
5. userFunction이 recordContext와 함께 처리됨 (workerThreadPool)
ParallelConsumer
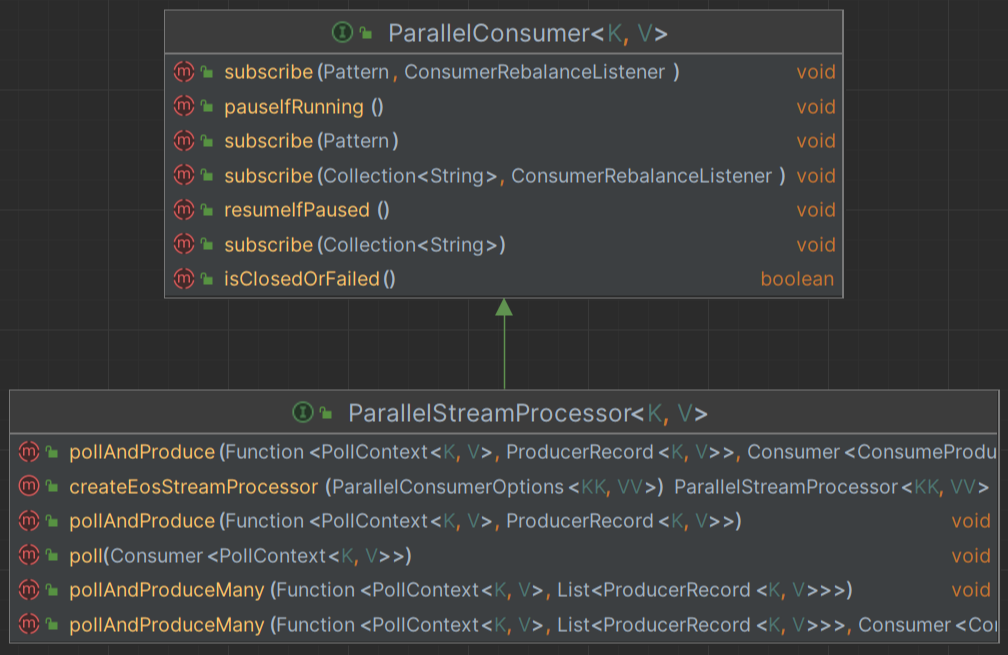
라이브러리의 핵심이 되는 interface이다.
일반적으로 사용자는 ParallelStreamProcessor의 poll 메서드를 통해 interact 한다.
Setup Parallel Consumer
ParallelStreamProcessor<String, String> setupParallelConsumer() {
Consumer<String, String> kafkaConsumer = getKafkaConsumer();
Producer<String, String> kafkaProducer = getKafkaProducer();
var options = ParallelConsumerOptions.<String, String>builder()
.ordering(KEY)
.maxConcurrency(1000)
.consumer(kafkaConsumer)
.producer(kafkaProducer)
.build();
ParallelStreamProcessor<String, String> eosStreamProcessor =
ParallelStreamProcessor.createEosStreamProcessor(options);
eosStreamProcessor.subscribe(of(inputTopic));
return eosStreamProcessor;
}공식 parallelConsumer Setup example이다.
일반적으로 ParallelEoSStreamProcessor.class를 사용하며, Reactor 환경에서는 ReactorProcessor.class를 생성하여 사용한다.
producer는 생략 가능하며, 순수 consumer로 사용할 수 있다.
ParallelEoSStreamProcessor.class → poll(…)
@Override
public void poll(Consumer<PollContext<K, V>> usersVoidConsumptionFunction) {
Function<PollContextInternal<K, V>, List<Object>> wrappedUserFunc = (context) -> {
log.trace("asyncPoll - Consumed a consumerRecord ({}), executing void function...", context);
carefullyRun(usersVoidConsumptionFunction, context.getPollContext());
log.trace("asyncPoll - user function finished ok.");
return UniLists.of(); // user function returns no produce records, so we satisfy our api
};
Consumer<Object> voidCallBack = ignore -> log.trace("Void callback applied.");
supervisorLoop(wrappedUserFunc, voidCallBack);
}
public static <PARAM> void carefullyRun(Consumer<PARAM> wrappedFunction, PARAM userFuncParam) {
try {
wrappedFunction.accept(userFuncParam);
} catch (Throwable e) {
throw new ExceptionInUserFunctionException(MSG, e);
}
}기본 구현체인 ParallelEoSStreamProcessor의 poll 메서드의 코드이다.
PollContext의 consumer를 parameter로 받고 wrapping 하여 supervisorLoop() 함수로 execute 시킨다.
PollContext<K, V>
public class PollContext<K, V> implements Iterable<RecordContext<K, V>> {
protected Map<TopicPartition, Set<RecordContextInternal<K, V>>> records = new HashMap<>();
...
}PollContext는 한 번에 poll 한 record를 context와 함께 가진 클래스이다.
사용자는 poll 정책에 따라서 record 1개 또는 여러 개 받아서 처리할 수 있다.
AbstractParallelEoSStreamProcessor.class → supervisorLoop(…)
protected <R> void supervisorLoop(Function<PollContextInternal<K, V>, List<R>> userFunctionWrapped, Consumer<R> callback) {
...
// broker poll subsystem
brokerPollSubsystem.start(options.getManagedExecutorService());
ExecutorService executorService;
try {
executorService = InitialContext.doLookup(options.getManagedExecutorService());
} catch (NamingException e) {
...
}
// run main pool loop in thread
Callable<Boolean> controlTask = () -> {
...
while (state != CLOSED) {
log.debug("Control loop start");
try {
controlLoop(userFunctionWrapped, callback);
} catch (InterruptedException e) {
...
}
}
log.info("Control loop ending clean (state:{})...", state);
return true;
};
Future<Boolean> controlTaskFutureResult = executorService.submit(controlTask);
this.controlThreadFuture = Optional.of(controlTaskFutureResult);
}위 함수는 poll task와 handle with userFunction task를 execute 하는 기능을 가진다.
이는
1. start poll task
2. start control(userFunction) task
- executorService를 lookup 하거나 생성한다. (정책에 따라서)
- controlLoop() 함수를 호출하는 task(callable)을 만든다.
- executorService로 submit 한다.
로 요약할 수 있다.
Poll Task 관련
BrokerPollSystem.class
public void start(String managedExecutorService) {
...
Future<Boolean> submit = executorService.submit(this::controlLoop);
...
}
private boolean controlLoop() throws TimeoutException, InterruptedException {
...
try {
while (runState != CLOSED) {
handlePoll();
...
}
...
}
private void handlePoll() {
...
if (runState == RUNNING || runState == DRAINING) { // if draining - subs will be paused, so use this to just sleep
var polledRecords = pollBrokerForRecords();
...
if (count > 0) {
...
pc.registerWork(polledRecords);
}
}
}
private EpochAndRecordsMap<K, V> pollBrokerForRecords() {
...
ConsumerRecords<K, V> poll = consumerManager.poll(thisLongPollTimeout);
return new EpochAndRecordsMap<>(poll, wm.getPm());
}
// private final BlockingQueue<ControllerEventMessage<K, V>> workMailBox = new LinkedBlockingQueue<>();
public void registerWork(EpochAndRecordsMap<K, V> polledRecords) {
...
workMailBox.add(ControllerEventMessage.of(polledRecords));
}poll task는 task별로 mailbox라는 Queue에 poll 한 결과(recordContext)를 add 하는 작업이다.
mailbox는 Threadsafe 한 blocking queue이며, control task에서 꺼내서 userFunction에서 사용된다.
AbstractParallelEoSStreamProcessor.class → controlLoop(...)
protected <R> void controlLoop(Function<PollContextInternal<K, V>, List<R>> userFunction,
Consumer<R> callback) throws TimeoutException, ExecutionException, InterruptedException {
...
if (shouldTryCommitNow) {
// offsets will be committed when the consumer has its partitions revoked
commitOffsetsThatAreReady();
}
// distribute more work
retrieveAndDistributeNewWork(userFunction, callback);
// run call back
log.trace("Loop: Running {} loop end plugin(s)", controlLoopHooks.size());
this.controlLoopHooks.forEach(Runnable::run);
...
}control task는 크게 3가지 역할을 가진다.
1. offset처리가 필요한지 체크해서 OffsetCommitter(BrokerPollSystem)에게 commit 트리거
2. userFunction 실행
3. callback 처리
성능
performance measurement by Confluent
- A random processing time between 0 and 5ms
- 10,000 messages to process
- A single partition (simplifies comparison - a topic with 5 partitions is the same as 1 partition with a keyspace of 5)
- Default ParallelConsumerOptions
- maxConcurrency = 100
- numberOfThreads = 16
| Ordering | Number of keys | Duration | Note |
| Partition | 20 (not relevant) | 22.221s | This is the same as a single partition with a single normal serial consumer, as we can see: 2.5ms avg processing time * 10,000 msg / 1000ms = ~25s. |
| Key | 1 | 26.743s | Same as above |
| Key | 2 | 13.576s | |
| Key | 5 | 5.916s | |
| Key | 10 | 3.310s | |
| Key | 20 | 2.242s | |
| Key | 50 | 2.204s | |
| Key | 100 | 2.178s | |
| Key | 1,000 | 2.056s | |
| Key | 10,000 | 2.128s | As key space is t he same as the number of messages, this is similar (but restricted by max concurrency settings) as having a single consumer instance and partition per key. 10,000 msgs * avg processing time 2.5ms = ~2.5s. |
| Unordered | 20 (not relevant) | 2.829s | As there is no order restriction, this is similar (but restricted by max concurrency settings) as having a single consumer instance and partition per key. 10,000 msgs * avg processing time 2.5ms = ~2.5s. |
Key 1개 + order == Single Thread이다.
key의 개수가 Thread Count(16)까지 유의미한 처리 속도를 보이며, 그 이후는 큰 차이를 보이지 않는다.
사실상 Key >= Thread Count 인 경우와 unordered는 성능 향상을 보이며, 동일한 퍼포먼스를 보인다고 볼 수 있다.
performance measurement by Naver
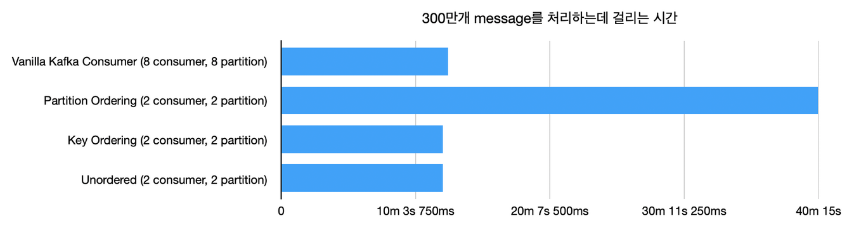
성능 측정 시 2 consumer(parallel), 2 partition이 8 consumer(일반), 8 partition과 유사한 성능을 보였다.
Conclusion
Parallel Consumer는 기존 Consumer에 병렬 처리를 더한 구현체이다.
유의미한 성능 향상을 보이지만, 관리포인트(config)가 늘어난다.
기본적으로 partition의 key에 대한 예측 및 관리가 필요하다.
정리하자면
- 도입 시 key 예측 및 추가적인 config 등 관리포인트가 늘어난다.
- 고부하 상황이 아니라면 유의미한 성능 향상을 기대할 수 없다.
- Conumser 교체, 추가적인 key 관리 (estimation)만 하면 되기 때문에 추후 도입이 용이하다.
// 메인 비즈니스의 변경 없이 도입 가능
따라서 partition을 늘리기 부담스러운 고부하 상황에서 도입하는 것이 타당할 것으로 판단된다.
REFERENCE
https://github.com/confluentinc/parallel-consumer
https://d2.naver.com/helloworld/7181840
반응형
'개발 일지' 카테고리의 다른 글
| Java Reactive Streams Publisher / Subscriber 분석 (projectreactor) (0) | 2024.03.26 |
|---|---|
| Spring Webflux with EventListener (0) | 2024.03.20 |
| TURN Protocol (+ STUN Message) (1) | 2024.03.18 |
| ProjectReactor Case Study (0) | 2024.02.22 |
| Global Hooks And Context Propagation (Projectreactor Advanced Features) (1) | 2024.02.20 |