반응형

개요
VoltDB 조사 및 사용성 검토
어떤 목적 및 사상을 가지고 있는지, 해결한 문제, 한계점 등을 파악
VoltDB란?
VoltDB는 기존 Database 대비 throughtput을 향상 시키기 위해 개발된 ACID를 준수하는 transactional database이다.
기존 DB는 범용성을 위해서 최적화 범위를 제한하였는데, voltDB는 이를 개선하고자 했다.
디자인 아이디어
- ACID 및 SQL 스펙을 만족하여 러닝커브를 줄임
- in-memory 방식을 통한 Disk-IO를 줄임
- data access를 serializing하여 locking, latching, transaction log 관리에 대한 오버헤드를 최소화
- clustering, replication을 통한 고가용성 및 안정성 확보
VoltDB 목적
Focus on handling fast data
VoltDB는 금융, SNS, IoT등 빠른 데이터 Store에 대한 문제를 해결합니다.
이는 scalability, reliability, high availability, high throughput을 지원함을 의미합니다.
SQL Support
SQL을 지원하기 때문에 상대적으로 낮은 러닝커브를 갖고 있습니다.
Inefficient for Large & complicated Data Structure
VoltDB는 히스토리성 데이터 같이 큰 데이터를 handling하기에는 부적합합니다.
또한 여러 테이블을 join하는 복잡한 데이터의 handling을 최적으로 지원하고 있지 않습니다.
Architecture Complicated
최적의 성능을 위해서는 설계의 복잡성이 증가합니다.
Stored Procedure 기반, partition 개념 등 설계 및 운용 시 고려해야 할 사항이 늘어납니다.
VoltDB Idea
1. In-memory processing
VoltDB는 DiskIO를 없에고, memory로 data store를 구성하여, performance를 향상시켰다.
2. Stored Procedure Interface
기존 Data Query는 네트워크 패킷의 overhead 및 Query 해석, 목적을 위한 다중 쿼리 전송 등 작업이 performance를 낮춥니다.
VoltDB는 Stored Procedure만을 호출하여 위 overhead를 one round trip으로 수행할 수 있도록 합니다.
또한 VoltDB는 하나의 procedure는 하나의 transaction을 의미하며, success 또는 rollback을 한 동작에서 가능하도록 합니다.
3. Serialized Processing

VoltDB는 1 DataAccess == 1 transaction 이다. 이 요청들은 serial하게 execution engine에서 실행된다.
Execution Engine은 VoltDB의 Partition 당 하나씩 생성되는데 이는 CPU cores와 cluster에 따라서 결정된다.
결론적으로 voltDB는 모든 요청을 serial하게 처리하여, lock 및 latch 없이 transactional한 처리를 지원한다.
VoltDB 동작원리
1. Partitioning
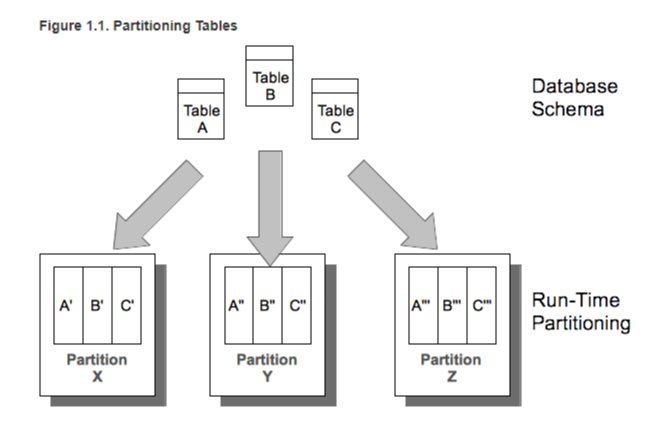
VoltDB는 모든 Stored Procedure를 Analyze하고 precompile하여 access data logic을 정리한다.
이 과정을 통해, voltDB는 실행환경(CPU Core등)을 고려하여 execute engine을 포함한 partition을 initialize한다.
각 partition은 기본적으로 유니크한 data의 집합을 가지고 있다.
2. Serialized Processing
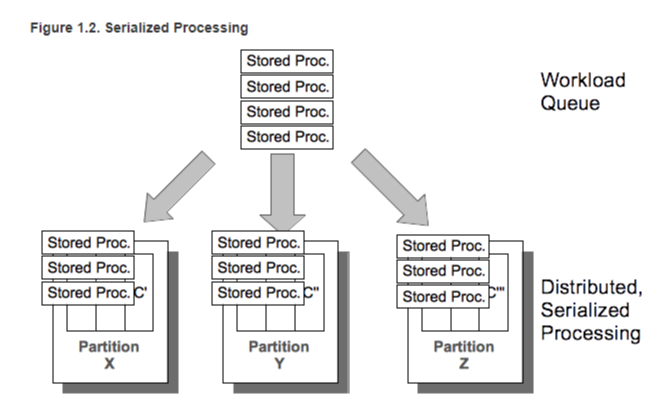
VoltDB는 모든 쿼리가 Stored Procedure로 동작한다. 또한 Stored Procedure는 하나의 transaction을 의미한다.
이는 하나의 쿼리 당 하나의 transaction을 의미한다.
모든 요청을 serial하게 처리하면 transaction을 고려한 lock 및 latch를 사용할 필요가 없어진다.
Stored procedure는 Analyze 단계에서 Single-partitioned 또는 Multiple-partitioned 2종류로 나누어진다.
Single-partitioned procedure는 다른 partition과 상관없는 procedure로 execute engine에서 parallel하게 동작한다.
Multiple-partitioned procedure는 연관 있는 특정 partition의 execute engine에서 다른 partition의 결과를 collect하는 방식으로 동작한다.
당연하게도 Multiple-partitioned procedure는 성능이 떨어진다.
3. Replication
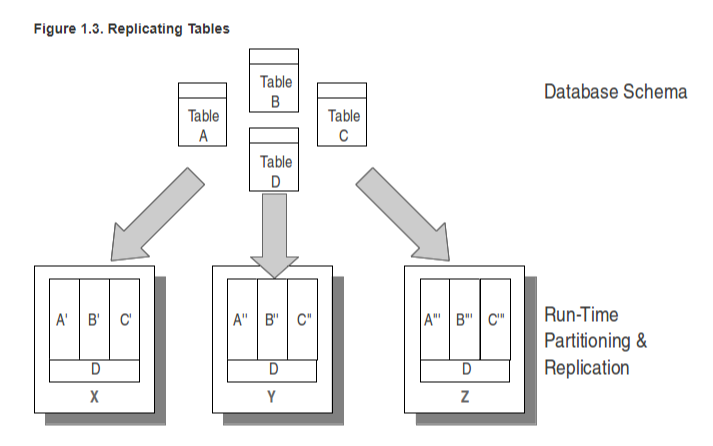
VoltDB는 Single-partitioned procedure가 최적의 성능을 제공한다.
이에 join을 위한 largely read-only table을 각 partition에 replication하는 기능을 제공한다.
위 그림의 D테이블은 read가 압도적으로 많으며, A,B,C간의 관계를 나타내는 테이블이다.
D테이블이 없는 partition은 항상 Multiple-partitioned procedure로 동작하면 불합리하기에, D 테이블을 파티션에 복제하여, 모두 Single-partitioned procedure처럼 동작할 수 있도록 할 수 있다.
VoltDB vs RDBMS(MariaDB) vs MongoDB vs Redis

| Name | MariaDB | MongoDB | Redis | VoltDB |
| Primary database model | Relational DBMS | Document store | Key-value store | Relational DBMS |
| Secondary database models | Document store Graph DBMS Spatial DBMS |
Spatial DBMS Search engine Time Series DBMS Vector DBMS |
Document store Graph DBMS Spatial DBMS Search engine Time Series DBMS Vector DBMS |
|
| DB-Engines Ranking | Score: 93.81 | Score: 423.96 | Score: 156.44 | Score: 1.46 |
| Initial release | 2009 | 2009 | 2009 | 2010 |
| Current release | 11.3.2, February 2024 | 6.0.7, June 2023 | 7.2.4, January 2024 | 11.3, April 2022 |
| License | Open Source | Open Source | Open Source | Open Source |
| Implementation language | C and C++ | C++ | C | Java, C++ |
| Data scheme | yes | schema-free | schema-free | yes |
| Typing (predefined dataType) | yes | yes | partial | yes |
| Secondary indexes | yes | yes | yes | yes |
| SQL | yes | Read-only SQL queries via the MongoDB Atlas SQL Interface | with RediSQL module | yes |
| APIs and other access methods | ADO.NET JDBC ODBC Proprietary native API |
GraphQL HTTP REST Prisma proprietary protocol using JSON |
proprietary protocol | Java API JDBC RESTful HTTP/JSON API |
| Triggers | yes | yes | publish/subscribe channels provide some trigger functionality; RedisGears | no |
| Partitioning methods | several options for horizontal partitioning and Sharding | Sharding | Sharding | Sharding |
| Replication methods | Multi-source replication Source-replica replication |
Multi-Source deployments with MongoDB Atlas Global Clusters Source-replica replication |
Multi-source replication Source-replica replication |
Multi-source replication Source-replica replication |
| Foreign keys | yes | no | no | no |
| Transaction concepts | ACID | Multi-document ACID Transactions with snapshot isolation | Atomic execution of command blocks and scripts and optimistic locking | ACID |
| Concurrency | yes | yes | yes | yes |
| Durability | yes | yes | yes | yes |
| In-memory capabilities | yes | yes | yes |
VoltDB는 일부 세부적인 항목을 제외하면, 전통적인 RDBMS와 상당히 비슷한 기능을 제공한다.
이는 RDB의 핵심 컨셉인 ACID transaction를 지원하기 때문이다.
VoltDB vs MongoDB (performance)
분산 환경에서 ACID transaction를 지원하는 두 DB의 성능을 비교 (MongoDB는 개념적인 ACID를 지원한다)
Test Env
CPUs: 2
RAM: 4GB
HDD: 8GB
OS: Windows Server 2016
Test Data

RDB 기준 Data 구조
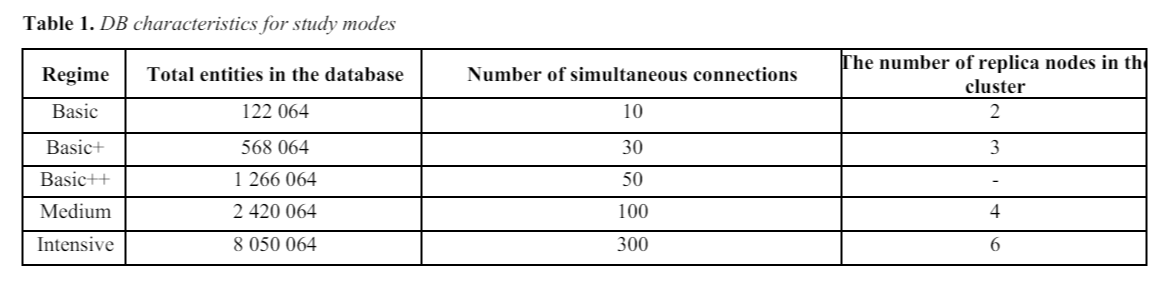
Connection 개수를 변경하면서 테스트를 진행한다.
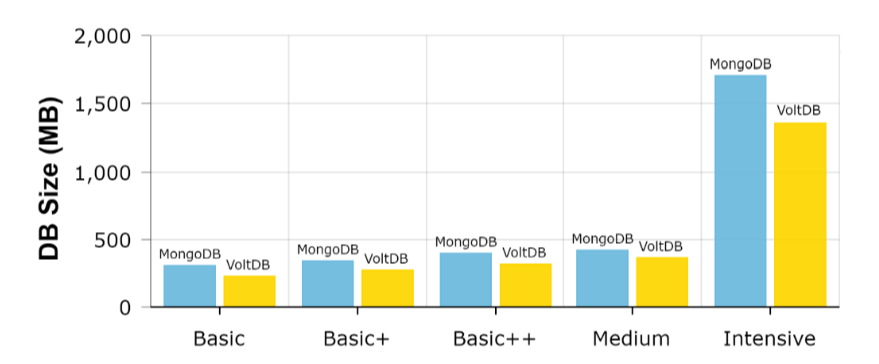
총 5 종류의 데이터 셋을 준비했으며, 개념적으로 같은 데이터를 각 DB에 맞게 구성했다.
Size로 보았을 때 MongoDB의 data overhead가 더 큰 것을 볼 수 있다.
CPU Usage

전체적으로 CPU 사용량은 VoltDB가 MongoDB보다 성능 상 이점이 있는 것을 볼 수 있다.
이는 VoltDB의 Stored Procedure의 execute가 보다 효율적인 것이라 예상해 볼 수 있다.
하지만, connection만 늘어나는 상황에서는 voltDB는 각 request를 serial하게 처리하기 때문에 상대적으로 좋지 못한 performance를 보인다.
Insert Test

Insert는 MonogoDB가 안정적인 성능을 보장하는 것을 볼 수 있다.
이는 insert 되는 Data의 partition 선정 등 작업에서 버든이 있을 것으로 추정된다.
Update / Delete Test
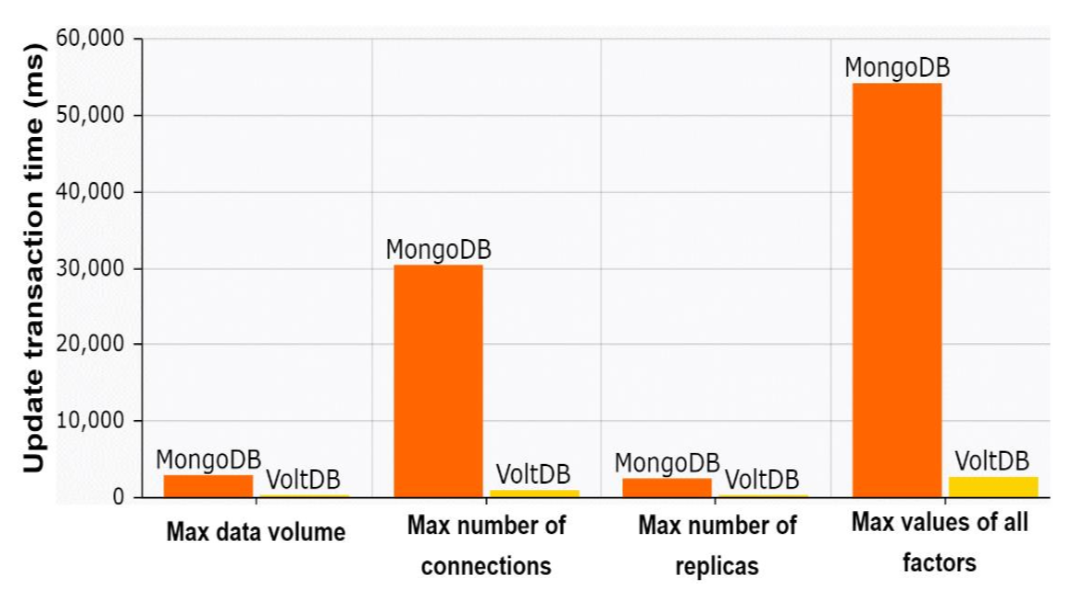

Update는 전반적으로 voltDB가 안정적으로 좋은 퍼포먼스를 보여준다.
이는 update를 위해서 전체 컬랙션을 full-scan하는 경우가 있기 때문에 MongoDB는 transaction처리를 위한 비효율이 발생하는 것으로 예상된다.
물론 index를 통해 성능 보정이 가능할 것이다.
반면 VoltDB는 RDB의 특성으로 인하여 transaction 처리에 이점을 가지며, 성능의 차이를 보인다.
VoltDB vs MongoDB 결론
기본적인 CPU 사용량은 VoltDB가 더 효율적이며, transaction 처리 성능에 큰 이점을 가진다.
하지만 대량 / 고부하 insert는 MongoDB가 더 좋은 결과를 보였다.
이에 VoltDB는 Schema가 정해져 있으며, update가 빈번하게 일어나며, transaction처리가 필요한 요구사항에서 최적의 성능을 낼 수 있음을 확인할 수 있다.
Conclusion
전통적인 RDBMS를 대체하는 상황
update가 빈번하게 일어나며, insert가 상대적으로 적은 상황
schema가 과도하게 복잡하지 않으며, single partition execute로 대부분의 쿼리가 가능한 상황
scale-out이 필요할 정도의 부하가 일어나는 상황
NoSQL을 대신할 수 있는 상황
ACID Transaction이 필요한 상황
총평
VoltDB는 ACID를 지원하는 Database이다.
전통적인 RDBMS의 빈번한 locking, latching의 비효율성을 개선하며, scale-out을 통한 수평적 확장을 효율적으로 보장한다.
기본적으로 update / delete에 큰 이점을 가지고 있으며, insert / select 또한 전통 RDBMS보다 좋은 성능을 낼 수 있다.
하지만 tradeoff 사항으로 복잡한 구조의 데이터를 쿼리하거나 큰 record를 쿼리하는 성능에 불이익을 가진다.
또한 DB의 특성을 고려하여 설계가 필요하며, 이는 stored procedure 기반 아키텍처, partition을 고려한 data 구조 등을 말한다.
결론적으로 RDB를 대체하거나 NoSQL을 대체하기에는 범용성이 부족하며
application에서 상당한 책임을 가져가는 요즘 추세에서 사용할 가치가 있는지는 의문이 있다.
REFERENCE
https://docs.voltdb.com/UsingVoltDB/
https://www.odbms.org/wp-content/uploads/2013/11/VoltDBTechnicalOverview.pdf
https://db-engines.com/en/system/MariaDB%3BMongoDB%3BRedis%3BVoltDB
반응형
'개발 일지' 카테고리의 다른 글
| Dead Letter Queue (DLQ) 패턴 (0) | 2025.02.13 |
|---|---|
| ksqlDB 란 (0) | 2024.05.27 |
| Java Reactive Streams Publisher / Subscriber 분석 (projectreactor) (0) | 2024.03.26 |
| Spring Webflux with EventListener (0) | 2024.03.20 |
| [Kafka] Parallel Consumer (0) | 2024.03.19 |