반응형

개요
카프카는 Queue를 베이스로 하여 데이터의 발행/소비를 인프라 적으로 격리시킨 시스템으로 볼 수 있다. 이런 격리된 프로세스는 확장성과 가용성을 제공하지만 운영 상 복잡성이 늘어나게 된다.
Queue의 데이터를 임의로 핸들링 하기 힘들다는 점을 집중적으로 분석하고 해결방안 또는 대처방안에 대해 정리하고자 한다.
Dead Letter Queue (DLQ) 패턴이란?
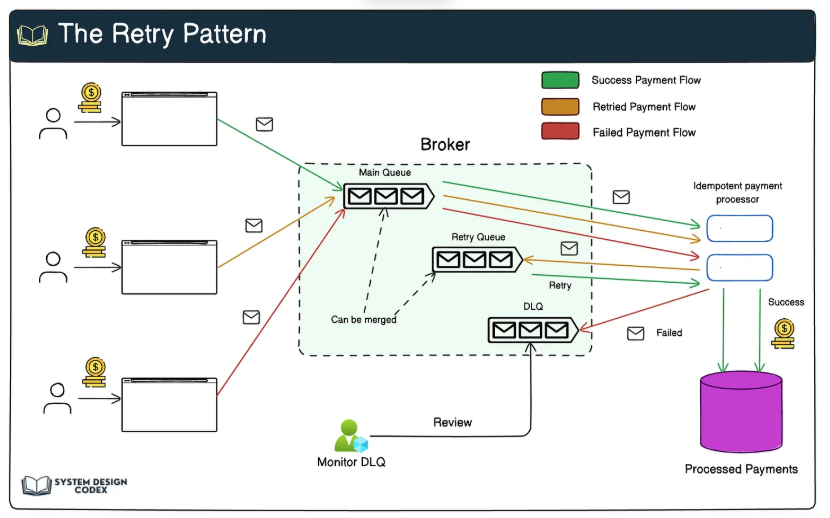
DLQ는 Consumer가 정상적으로 처리하지 못한 메시지를 따로 저장하는 Kafka의 보조적인 토픽
즉, 오류가 발생한 메시지를 다른 곳에 보관하여 이후 다시 처리할 수 있도록 하는 전략
DLQ 핵심 전략
- Consumer가 메시지를 처리하는 도중 오류 발생
- 오류가 발생한 메시지를 DLQ 토픽에 저장
- DLQ에 저장된 메시지를 모니터링 및 분석
- DLQ에 저장된 메시지를 별도의 프로세스로 재처리
DLQ 패턴의 의미
DLQ 패턴은 처리하지 못한 데이터를 적극적으로 핸들링하기 위한 방법입니다.
따라서 DLQ 모니터링과 분석이 필수적이라 여겨집니다.
궁극적으로 모니터링 도구와 연동으로 개발자가 에러의 원인을 빠르게 파악하고 재처리하여 전체 시스템의 신뢰도를 높일 수 있는 방법이란 의미가 있습니다.
장점
1. 데이터 유실 방지 & 보존 가능 + 메시지 재처리/복구
Kafka에서 Consumer가 메시지를 정상적으로 처리하지 못하면 기본적으로 재시도 없이 메시지가 손실될 가능성이 있다 DLQ를 사용하면 실패한 메시지를 안전하게 저장하고 나중에 재처리 가능, 데이터 유실을 방지할 수 있다
DLQ에 저장된 메시지를 특정 시점 이후에 다시 정상 토픽으로 재전송하여 재처리 가능재처리 로직을 통해 일괄적으로 복구하거나 특정 메시지만 선택적으로 복구 가능
2. 모니터링 이점 및 장애 발생 시 신속한 대응 가능
실시간으로 Kafka Consumer가 처리하지 못한 메시지를 DLQ에 쌓이도록 설정하면 장애 감지 및 대응이 쉬워 짐 DLQ에 특정 유형의 메시지가 급격히 증가하면 Consumer의 코드 오류 또는 다운타임 발생 가능성을 빠르게 인지할 수 있다.
이는 에러로그 사후분석에 비해 효율적이며, 상황에 따른 트리거링도 가능하다.
3. 비즈니스 로직에 따른 맞춤형 처리 가능
특정 비즈니스 요구사항에 따라 DLQ에 쌓인 메시지를 다양한 방식으로 처리 가능
실패한 메시지를 즉시 재처리할지, 특정 시간 이후에 다시 시도할지, 별도 데이터베이스에 저장할지 등을 설정 가능
단점
1. 시스템 복잡도 증가
DLQ를 도입하면 기존 Kafka Consumer와 함께 추가적인 DLQ Topic, DLQ Consumer, 재처리 로직 등이 필요 이러한 복잡성 증가로 인해 운영 부담이 커지고 유지보수가 어려워질 수 있음 또한 DLQ로 전송하는 로직도 구현해야 하며, 모니터링 시스템까지 구축해야 높은 효율을 보인다.
이러한 복잡도는 운영 요소의 증가로 이어진다.
2. DLQ 메시지가 쌓이면 운영 부담 증가
DLQ 메시지를 재처리하지 않으면 계속해서 쌓이고, 결국 스토리지 비용 증가한다.
또한 너무 쌓인 데이터는 분석 및 핸들링에 어려움을 가져와 DLQ 패턴의 도입 이점이 희석될 수 있다.
3. 메시지 재처리 시 데이터 순서 유지 어려움
Kafka의 메시지는 Partition 단위로 순서를 보장하지만, DLQ에 저장된 메시지를 다시 처리할 때는 순서가 깨질 가능성이 높음
이를 해결하려면 일부 메시지를 특정 시점에만 재처리하도록 조정하거나 다른 timestamp를 기준으로 재정렬하는 로직이 필요하다.
하지만 운영이 복잡해짐
DLQ 도입 고려 요소
| 도입이 적절한 경우 | 도입이 불필요한 경우 |
| - 데이터 유실을 절대 허용할 수 없는 시스템 (예: 금융 거래, 주문 시스템) - Consumer가 일시적으로 장애가 발생할 가능성이 있는 경우 - 메시지 처리 오류가 발생할 수 있는 복잡한 비즈니스 로직을 운영하는 경우 - Kafka Consumer의 안정성을 높이고, 운영 효율성을 개선하고 싶은 경우 |
- 메시지 처리 속도가 가장 중요한 실시간 시스템 (DLQ에서 재처리하는 시간이 부담이 될 수 있음) - Consumer 코드가 안정적이고, 장애가 거의 발생하지 않는 경우 - Kafka의 기본적인 재시도 및 에러 핸들링 기능만으로 충분한 경우 |
False Data 유입 상황
무중단 Producer/consumer 배포 시 record 호환성 문제
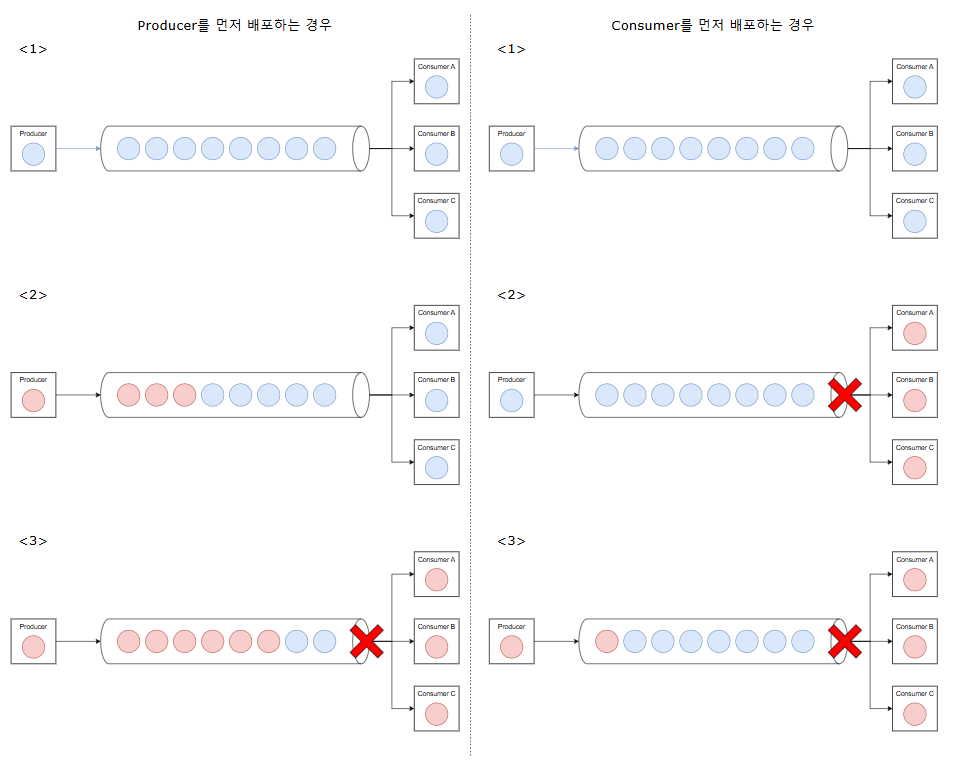
scale-out 구조에서 흔하게 발생하는 문제로 무중단 배포 시 일부 데이터가 처리되지 못해 유실되는 상황이다.따라서 무중단 배포 시 다음과 같은 상황 별 대처 방안이 필요하다.
- 데이터 누락이 허용되는 경우
- 데이터 누락이 허용되지 않는 경우
Human Error가 포함된 배포
Producer나 Consumer의 record 발행/소비의 유지보수 과정에서 예상하지 못한 error가 발생할 수 있다.
리뷰나 스테이징 운영을 통해 최대한 줄일 수 는 있지만 원천 차단은 불가할 것이다.
해결 방안
1. 데이터 누락 허용의 경우
데이터 누락이 허용되는 경우 consumer의 예외 및 skip처리를 구현해 놓으면 된다.
이후 효율성을 위해 producer → consumer 순으로 배포하면 된다.
2. 데이터 누락 허용 불가의 경우
2-1) Topic 분리 (version or temp 토픽)

호환 불가능한 record를 임시로 수용할 temp 토픽 또는 v2 토픽을 통해 무중단 배포하는 방식이다.
2-2) DLQ 패턴 적용

DLQ 패턴은 시스템 신뢰도를 높일 수 있는 방법으로 패턴 특성 상 무중단 배포에서 발생하는 이슈를 커버해 줄 수 있다.
Conclusion
- Kafka 무 중단 배포, 휴먼 에러 등 여러 이유로 처리되지 못하는 record가 발생할 수 있다.
- Topic 분리를 통해 처리되지 못한 record를 발생시키지 않을 수 있다.
- DLQ 패턴을 도입하여 처리되지 못한 record를 전반적으로 관리할 수 있다.
- DLQ는 Kafka 운영 환경 시스템의 신뢰도를 높일 수 있는 좋은 방법 중 하나이다.
- DLQ는 추가적인 개발 및 운영 비용이 들어간다.
REFERENCE
https://rudaks.tistory.com/entry/신뢰성-오류-복구-패턴-데드-레터-큐Dead-Letter-Queue-패턴
반응형
'개발 일지' 카테고리의 다른 글
| VoltDB란 (0) | 2024.06.03 |
|---|---|
| ksqlDB 란 (0) | 2024.05.27 |
| Java Reactive Streams Publisher / Subscriber 분석 (projectreactor) (0) | 2024.03.26 |
| Spring Webflux with EventListener (0) | 2024.03.20 |
| [Kafka] Parallel Consumer (0) | 2024.03.19 |